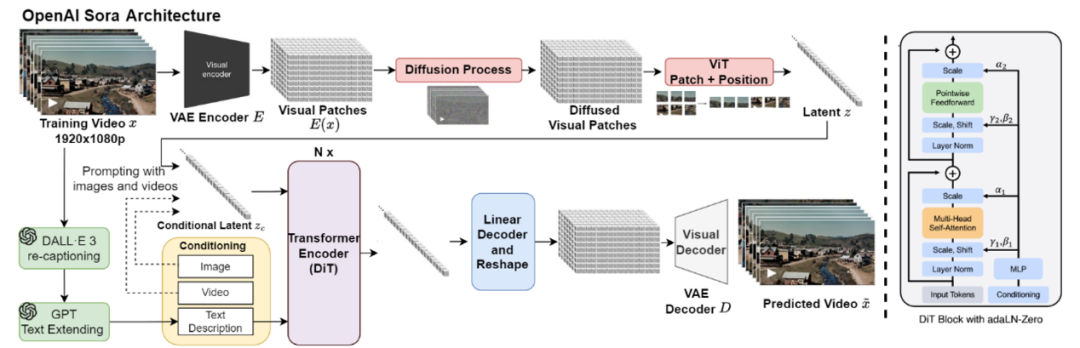
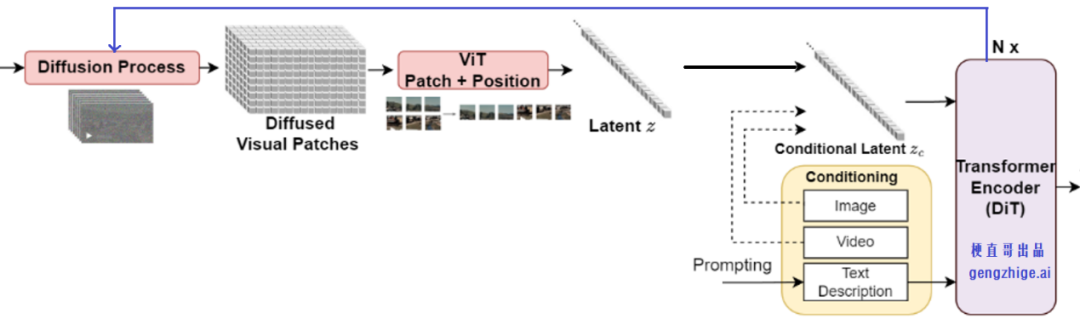
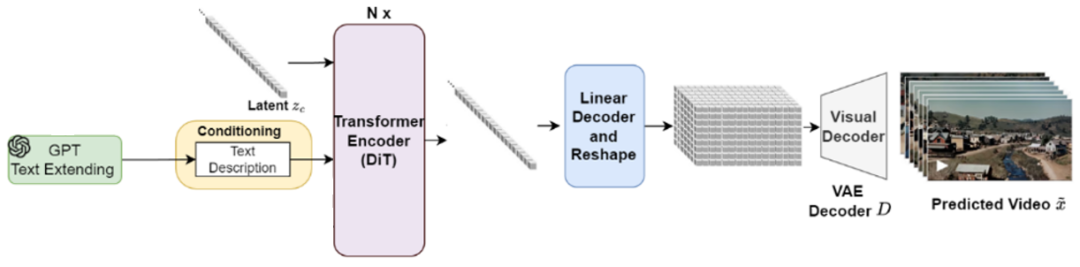
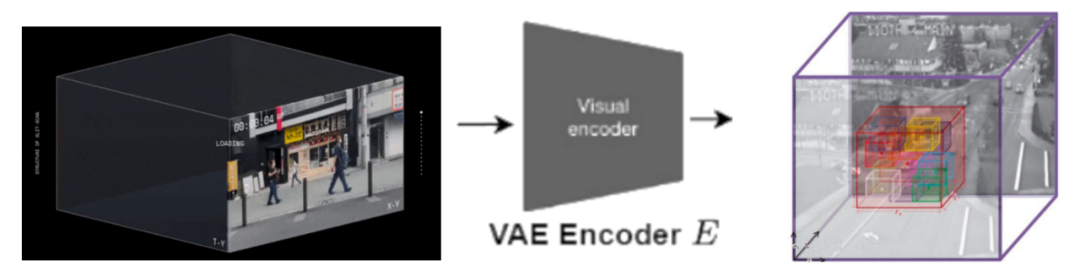
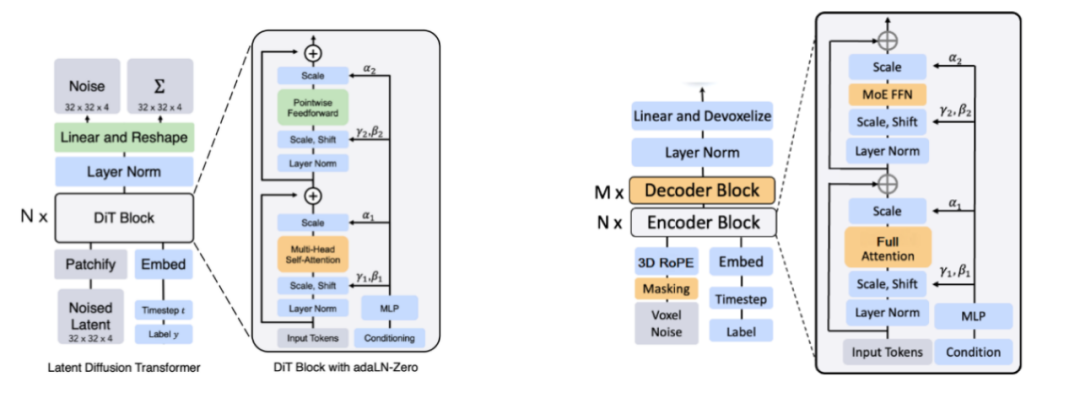
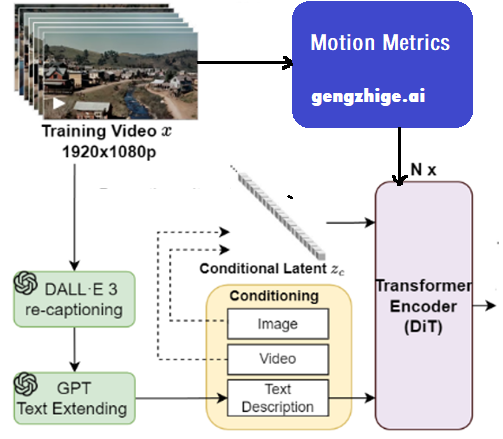
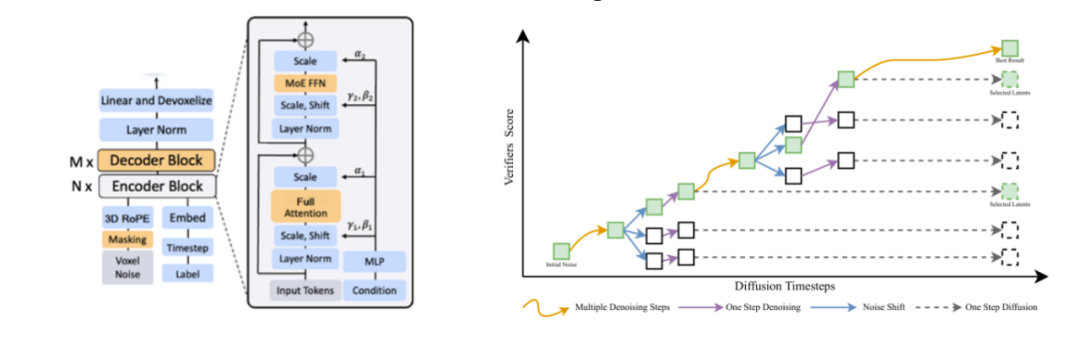
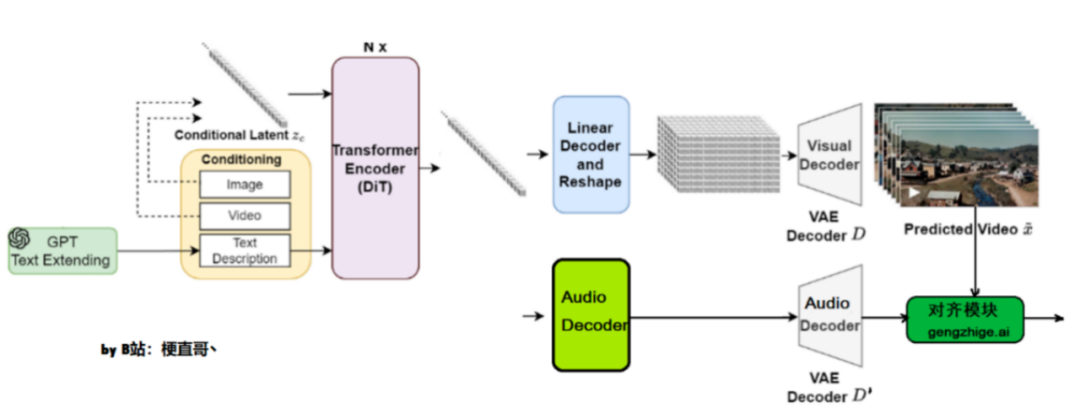
Sora2技术原理专业拆解,小白也听得懂! menglar-adm Linkpix图像生成、LinkPix图生视频、商品图片|视频ai 2025-10-10 11 分钟阅读 Sora 2这次最大的进步有仨: 一是它开始尊重世界的物理规律了,在处理复杂运动学和人物身体力学方面,都有了显著提升; 二是提供了更准确的物理效果和更清晰的细节,使得视频更逼真; 三是终于有声有色,不再是哑巴。给视频配上了灵魂,同步生成对话、音效和背景音乐,让画面和声音完美匹配。这是最具杀伤力的升级,没有之一。 与此同时,openAI还发了个新“赛道”Sora App,以生成和“二创”AI短视频为主的垂直内容平台,虽然仍处于需要邀请码的“饥饿营销”模式,但已经被玩嗨了。其中的“Cameo”功能,堪称王炸。用户可以通过一次身份验证,把自己的肖像和声音植入到AI生成的视频中,成为其中的角色。 那么,这次堪称“工业级”的更新在技术上有啥牛逼之处?原理侧该怎么深入浅出地理解?对视频生成、视频剪辑领域下一步有哪些冲击?对AI研究又有哪些新启发和新ideas呢? 一、关于“尊重物理规律”的提升 看着逼真的效果,很多人会惊呼Sora 2.0是不是高仿物理世界了,这是真的吗?到底有没有世界模型? 要整明白它是如何做到的,咱们先快速复习Sora 1.0的原理: 首先把训练视频经过VAE 编码器,压缩成一堆时空特征块。经过扩散过程加入噪声,让图像变得模糊,再加入位置信息token化,接着压成潜变量z。这个流程就像是把牛奶提炼成奶粉,去掉多余体积,只留下精华。再接着把z喂给Diffusion Transformer(DiT),并根据左边DALL·E 3+GPT给定的图像和文本提示,指导模型生成什么内容、场景或风格,也就是再从奶粉冲泡成不同奶茶、拿铁的过程。右图DiT模块展示了内部结构,每层都有注意力机制和条件控制模块,确保理解上下文、保持连贯性,并根据指令调整风格。 这张图里有很多细节是理解Sora的关键,也是Sora2改进的秘诀,我们分别看下。 训练阶段,在扩散过程和DiT之间反复进行“加噪、去噪”,让模型不断学习,掌握其中的规律。也就是在DiT和Diffusion Process之间有条“之字型”循环线,这里省略了反向去噪过程。 特别注意的是,这个过程中条件控制很重要,会根据文本提示词动态随机从原视频中抽帧,抽视频提取特征,进行数据增强灌入潜变量z中,形成多模态条件对齐。最后再用 VAE 解码器把潜空间中的特征重新还原成高清视频,如同重新把奶粉冲泡成牛奶。 推理阶段GPT对提示词扩写并语义细化,经过文本编码灌入潜空间作为生成条件,然后DiT模型从潜空间中多步迭代,再经过VAE解码器“重建”视频。此时,通常情况下没有image/video条件了。 那么,Sora 2.0做了什么神奇的改进呢? 技术角度看,核心仍是“生成模型 + 时空学习”,暂时并不是显式物理仿真,没有引入过多物理引擎、方程约束或可微物理层。其性能提升主要来自以下几方面: 1.三维时间-空间建模 旧版Sora用的是Stable Diffusion图像VAE直接改的2D模式,一帧一帧地去理解。Sora2采用了 3D Autoencoder结构,在“压缩视频”的时候,同时考虑“每一帧的画面”和“前后帧之间的变化”,相当于看一小片段。简单理解,就是在“看视频”时,把时间和空间一起看。 具体来说,用时域下采样技术在时间维度采样,狠抓动作节奏。同时,用空间像素重排 (pixel shuffle),让压缩后的特征更紧凑,捕捉光影变化。这种 3D 结构能更好的学习物体运动的连续性,减少穿模、漂浮、重影等违背物理规律的现象。它有点像一台“能看懂时间的摄影机”,不只是压缩图片,而是压缩一段时间。 2.全注意力 (Full Attention) Diffusion Transformer Transformer 就像模型的大脑,负责理解每个时刻、每个位置之间的关系。Sora 2 在这里做了两个重要升级。 首先,早期的 Sora 或类似的 video diffusion 模型(例如 VideoPoet、Pika、Runway Gen-2),底层结构大多都是二维图像模型改的“2D 编码 + 时序拼接”,是假 3D,并没有真正理解动作。同时,为了省算力,旧版采用“局部注意力”或“块状注意力”,只看临近几帧或局部区域。因此,生成时经常导致人的动作衔接不顺、物体漂移、光影闪烁或重影等问题,是个散光眼神。Sora 2 改成3D全注意力,也就是每一帧都能直接看到整段视频中所有其他帧的特征,而是立体块直接学,真正理解了时间的存在。比如,一个人从起跳到落地,能“一口气看到”全过程,而不是只靠局部片段瞎猜了。 其次,采用了3D Rotary Position Embedding (3D RoPE),也就是旋转位置编码。这个技术目的是告诉 Transformer “词或帧的顺序”。以前用的是2D RoPE,只知道平面上像素位置。现在把时间也当作一个轴,让模型知道“这个点在画面里的位置 + 属于第几帧 + 时间先后顺序”,因此能在时间维度上感知因果方向,知道“先发生什么、后发生什么”,从而生成的运动轨迹更符合现实逻辑。 上面两个改进都是典型的“升维思想” + “不差钱逻辑”,先解决问题再说。整体上都是在模型架构上做文章,工程优化。 模型“脑回路”改完了,为了进一步提升运动效果,Sora 2.0又增加了单独信号源来强化。 3.运动强度 (Motion Metrics) 控制 为每个视频打个分,评估这段视频里动得快还是慢,作为独立条件输入模型。相当于从视频计算分数旁路增加了一条线进入DiT。训练时模型就能学会区分“运动的幅度和节奏”,推理时只要调这个分数,就能控制画面运动的速度和稳定性,让镜头不乱晃、动作不僵硬,也不会超现实地快。改善了快慢和流畅度的控制问题,但不是用物理公式算的。 这算是某种轻量级的世界模型,训练时一定要加,用来监督信号。推理时可选,比如用户可以通过参数控制实现类似“镜头运动速度滑杆”效果。 4.图像-视频条件融合与动态引导 刚提到了多模态条件对齐,也就是这个text2image2video 条件框架。听上去文绉绉的,其实就是训练阶段,在输入Transformer的提示条件上做文章,实现动态调整文本、图像和视频的权重比。text指导“做什么”, image指导“长什么样”, video决定“怎么动”,让生成的视频既听得懂语义,又不会画面死板或乱晃,提升画面的物理连贯性与自然性。比如:文本提示词说“一个女孩在雨中跑步”, image提供生成与图像相似风格的视频,video提供动作或镜头参考,让 Transformer 同时听“文字教练”、“图像导演”、“视频摄像师”的指令,实现“语义理解 + 视觉外观 + 动作逻辑”三者的对齐。这一步是模型学会多模态融合的关键。 推理阶段,默认只有“文字教练”,但你也可以请“图像导演”或“视频摄影师”回来客串,提供图像或视频引导,类似Cameo功能就是这样实现的。 5.推理阶段的噪声缩放 (Inference-time Scaling) 这步发生在DiT肚子里,adaLN / Condition 调制模块控制噪声强度,相当于冲奶粉的时候的水流大小。水加太猛,噪声太大,奶粉冲不匀,画面乱;水加太小,噪声太弱,奶粉冲不开,画面僵硬。水流稳,奶粉溶得匀,生成的视频更平滑、更真实,显著改善物体的连贯运动与光影变化。右图是这个动态去噪过程的可视化,横轴是从纯噪声到清晰图像的逐步生成过程,纵轴是得分,紫线多步去噪慢但是稳、蓝线是一步去噪快但风险高,虚线是噪声跳步加速推理,黄色是最佳路径、动态调整噪声步幅,控制“水流大小”,曲线平滑上升,视频更自然平滑。 到这里,想必你已经有种“哇,我居然这么容易就理解了Sora 2”的感觉。是的,我们用一张大的流程图解释了几乎所有的改进。如果你喜欢梗直哥的讲解,加个关注吧。 除了上面模型架构和训练推理逻辑上的改进,在数据层面上,Sora 2也必然优化了高质量动态视频过滤与标注技术,以便减少不自然运动样本对训练的干扰,也通常是很关键的工程改进。 总体来说,基于公开文献及实测效果分析,我们有理由判断:Sora 2还是在沿用大规模视频数据学习“隐式物理一致性”(implicit physics priors)这样一条原有道路。这些机制不是显式物理公式,而是某种“结构先验(inductive bias),通过对网络结构和训练数据的设计,让模型学出来连贯的、可解释的时空模式。它在统计意义上学会了现实世界的部分规律性模式,但并非真的加入了world-model。即便有,目前对它的依赖性也很弱,还尚早。但无疑,它已经为未来世界模型的引入准备好了接口,具体怎么操作因为学术性较强,我们在内部分享再更深层剖析(https://t.zsxq.com/Fyl7n)。 二、物理与细节提升:更“真实”的世界 System Card及技术报告等参考文献显示,这种提升主要来自以下机制: 首先,三维时空建模(3D Autoencoder + DiT)。在潜空间中同时建模 x-y 空间与 t 时间,使每帧之间的运动连续、平滑,减少漂浮和穿模。这本身就会让视频中人物、光影和摄像机运动更符合真实物理规律的同时,实现更加清晰、丝滑的表现力。 其次,高质量训练策略。先在 256 px 低分辨率学习多样运动模式,再在 768 px、1080px等更高分辨率微调。这种“先学动作、再补细节”的分层训练会大幅提升清晰度与运动一致性。这也是文生图、文生视频的惯常操作。高分辨率 fine-tune,重点学“纹理、光影、细节与稳定性”, 相当于给已经会动的骨架“加上皮肤和质感”。 第三,多模态语义对齐(例如:T5-XXL + CLIP-Large)。这是目前顶级文生视频模型的“语义中枢”。文本与视觉特征的双编码方式会让画面理解语义更精确,从而减少不合逻辑的运动或物体错位现象。例如“左手举杯”不会生成成右手,“跳舞”不再被误生成成“走路”。这是多模态一体化的胜利! 总体上,Sora 2 通过结构设计和分级训练,让模型隐式学习了现实世界的动力学模式,在镜头运动、人物身体力学和场景交互上更自然、更真实。 三、声音与画面同步:让视频“有了灵魂” “有声有色”在感官上惊艳,但技术难度相对前面符合物理规律改进难度其实要低很多。生成同步音频(speech、BGM、环境音)看起来新奇,但本质上属于 跨模态对齐问题(audio-video alignment),技术路径在业内早已成熟。比如:音频生成模型(如 AudioGen、MusicLM、Jukebox 等)早已能从文本生成自然声音;对齐模块(alignment module)只需让音频节奏与视频帧率对齐。 虽然Sora2未披露具体算法,但从 OpenAI 现有多模态管线我们可以合理推测,它采用了统一多模态扩散框架。如图所示,也就是音频与视频在同一潜空间下生成或后期对齐,使脚步声、对话、环境声与画面动作同步。模型理解场景语义后,自动匹配相应的听觉事件(如海浪声、引擎声、对话语气),实现“画面-声音-语义”一体化。其中对齐模块(alignment modules),通过训练对齐时序标签,使音频节奏与视频帧率保持稳定同步。“哑巴”终于开口说话了,还能唱歌,给BGM。 四、新商业化赛道来啦 这次OpenAI不光是发了个模型,它还发了个新“赛道”Sora App,以生成和“二创”AI短视频为主的垂直内容平台。其中牛掰“Cameo”功能可以说是用户最爱,把自己的肖像和声音植入到AI生成的视频中,成为其中的角色,这显然是奔着夺取注意力去的。视频是最强的注意力载体。这意味着生产力被拉升了一个数量级。信息流会更密集,叙事更精准,操控注意力的门槛更低。过去,一个广告、一条短视频的制作,需要团队、设备和周期,现在成本骤降、速度极快,迭代无限。 我们有理由预期模型侧百花齐放,应用端群魔乱舞的局面必将继续,线上视频生态进一步混乱。人类的“真shan美”价值继续受到拷打,心痛所有视频审核同学们。关于搞钱和专业变现,我们内部分享敞开了讲。 参考文献: OpenAI 官方《Sora 2 System Card》(2025 年 9 月 30 日) Ntavelis E, Siarohin A, Olszewski K, et al. Autodecoding latent 3d diffusion models[J]. Advances in Neural Information Processing Systems, 2023, 36: 67021-67047. Wang Z, Li D, Wu Y, et al. Diffusion models in 3d vision: A survey[J]. arXiv preprint arXiv:2410.04738, 2024. Geng D, Herrmann C, Hur J, et al. Motion prompting: Controlling video generation with motion trajectories[C]//Proceedings of the Computer Vision and Pattern Recognition Conference. 2025: 1-12. Peng X, Zheng Z, Shen C, et al. Open-sora 2.0: Training a commercial-level video generation model in $200 k[J]. arXiv preprint arXiv:2503.09642, 2025. Fu X, Liu X, Wang X, et al. 3dtrajmaster: Mastering 3d trajectory for multi-entity motion in video generation[J]. arXiv preprint arXiv:2412.07759, 2024. 本篇文章来源于: 梗直哥 AI视频生成 Sora2技术 视频生成原理 menglar-adm 暂无介绍.... 上一篇 Sora2:AI视频的“GPT-3.5”时刻 下一篇 OpenAI突然发布Sora 2:好一个“AI版抖音”! 邮箱(必填): 清除信息 昵称(必填): 网址: 允许浏览器记住您的信息! 提交信息 Loading... 取消回复 发表评论 Loading... 评论列表 (0条): 热门 最新 加载更多评论 Loading... 延伸阅读: 热度 时效 暂无内容!


评论列表 (0条):
加载更多评论 Loading...