
你是否也曾有过这样的经历:脑子里有一个绝妙的视频点子,但一想到繁琐的制作流程就望而却步?
我完全理解!因此,我最近一头扎进了神奇的 AIGC 工作流世界,想和大家分享我的最新探险成果。

前段时间我迷上了Dify 的工作流,并给自己定了一个小目标:我能搭建一个工作流,仅用一句话就能直接生成视频吗? 这个过程可以说是一波三折,充满了“原来如此”的顿悟和“这到底是什么”的困惑,但好在最后我总算把思路理顺了。
为了防止自己忘记,也为了和大家分享这个探索过程,我把我那几张乱糟糟的草稿纸整理了出来 。 如果你对 Dify 感兴趣,或者想知道如何将“文生图”和“图生视频”这些功能巧妙地串联起来,那么这篇文章应该能给你一些启发。
一、灵光一闪:一切从一张潦草的思维导图开始
我最初的想法非常直接:输入一句话,输出一个视频。为了理清头绪,我铺开纸,画下了我的第一版思维导图。
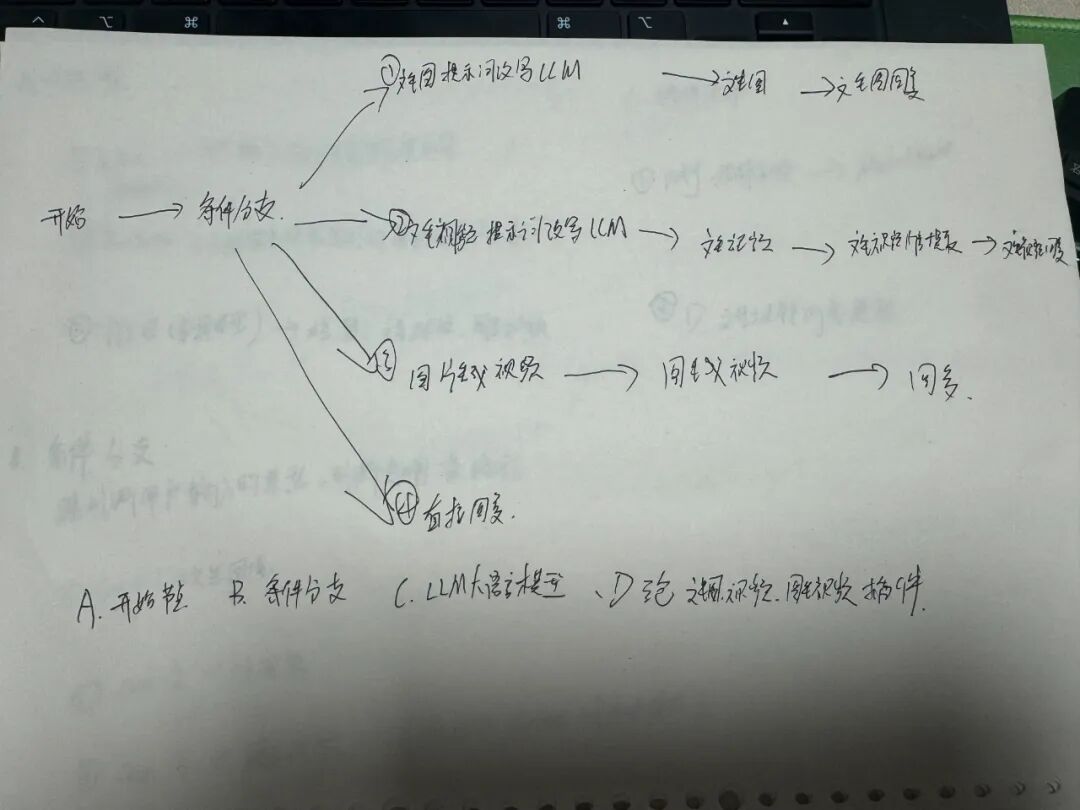
核心思路是利用一个叫做“条件分支”的节点——你可以把它想象成AI工作流的“交通指挥员”。它会判断用户的意图,然后将请求分配到正确的路径上。
我规划了这几条核心路径:

-
路径①:文生图 🖼️ 如果你想要一张图片,AI会接收你的文字,通过大语言模型(LLM)去理解和优化它,最后调用工具生成图片。
-
路径②:文生视频 🎥 这条路就更有意思了。AI会先根据你的文字生成一张图片,然后再让这张图片动起来,最终输出视频。
-
路径③:图生视频 🎞️ 如果你已经有了一张图片,想让它动起来,那就走这条路。
我的顿悟时刻:画完这张图,我豁然开朗!一个强大的“文生视频”工作流,其本质就是 “文生图” + “图生视频” 两个步骤的串联!
二、拆解流程:定义输入、场景和工具
有了整体框架,接下来就是细化。我需要明确地告诉 Dify,在不同情况下,它需要从用户那里获取什么信息。

于是,我将整个流程拆分成了几个核心“Case”(场景):
Case 1:文生图
-
需要什么: 只需要你输入的一段文字(Prompt)。 -
它做什么: 直接调用文生图工具。
Case 2:文生视频 (我的“组合技”)
-
需要什么: 同样只需要一段文字 Prompt。 -
它做什么: 这是最关键的一步。上一步“文生图”生成的图片,会自动成为下一步“图生视频”的输入数据。
Case 3:图生视频
-
需要什么: 你上传的一张图片,以及一段描述希望它如何运动的文字。 -
它做什么: 直接调用图生视频工具。
三、我的AI工具箱:装备精良才能事半功倍
思路和流程都清晰了,就差选择合适的工具来实现了。以下是我为这个项目挑选的“弹药”:
-
文生图 (Text-to-Image) 模型我这里用的是火山方舟的豆包模型,也可以选择 Stable Diffusion 或 DALL-E3,这些都可以在 Dify 中作为工具节点调用。
-
图生视频 (Image-to-Video) 模型要让静态图片动起来,Stable Video Diffusion (SVD) 和 EMU Video 是目前比较主流的选择,这里依旧使用火山方舟的豆包模型。
-
文生视频 (Text-to-Video) 模型虽然市面上有很多这样可以直接把文字生成视频的模型,但我发现,通过“文生图 -> 图生视频”这种“组合技”的方式,在 Dify 里的实现更灵活,效果也更容易控制。
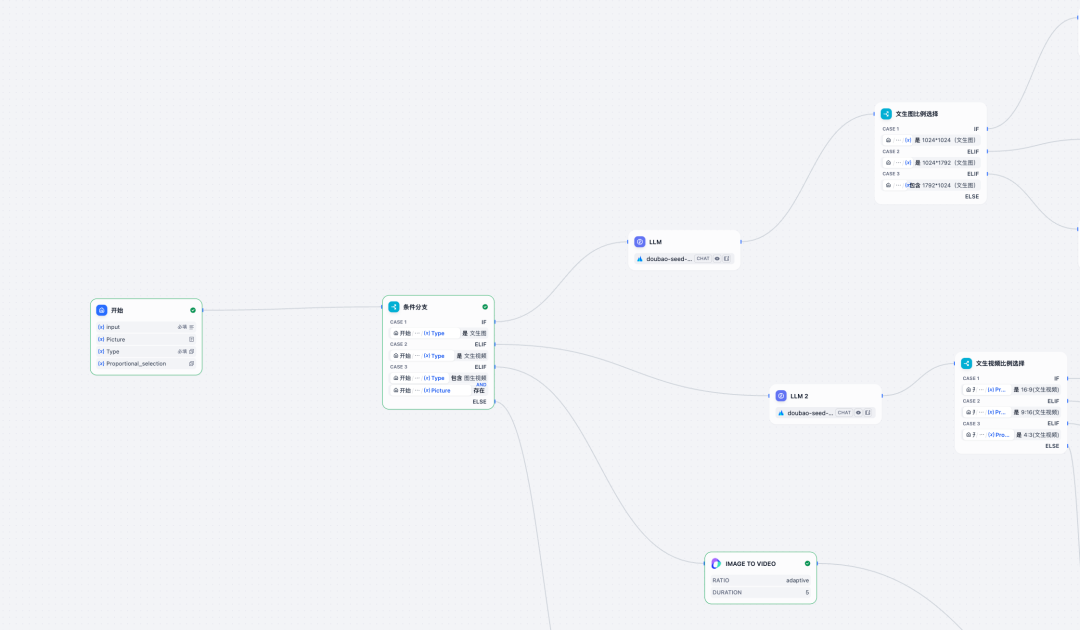
四、我的5步Dify工作流搭建逻辑
好了,把以上所有的思考碎片拼凑起来,我的最终工作流搭建逻辑就出炉了。
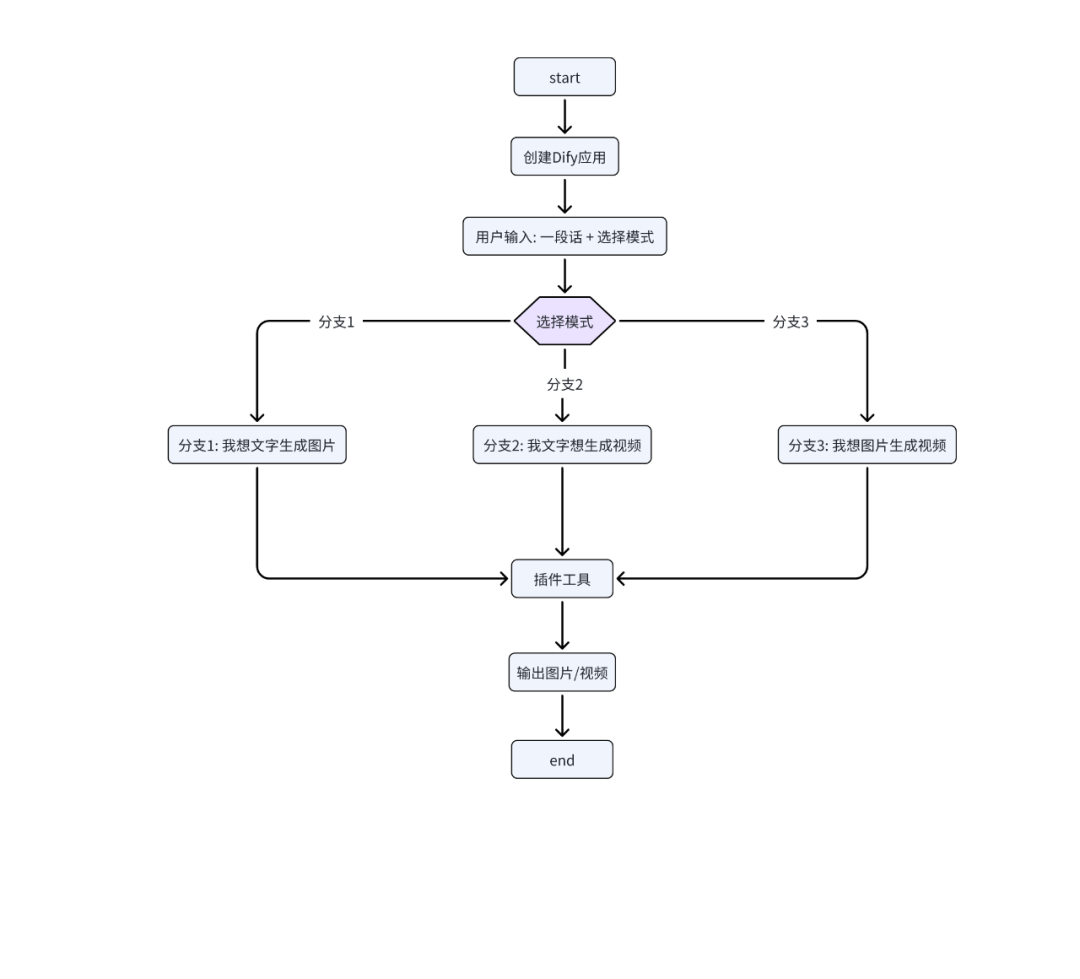
用大白话总结一下我的搭建步骤:
-
设置起点:创建一个工作流,设置一个“开始”节点,让用户可以输入文字,并提供选项(比如“要图”还是“要视频”)。
-
添加大脑 (条件分支):拉入一个“条件分支”节点,它会根据用户的选择,决定工作流接下来的走向。
-
搭建“文生图”分支:连接一个文生图工具(如 Stable Diffusion),并将用户的输入文字传递给它。
-
搭建“文生视频”分支:这条路稍微复杂一点。先连接一个文生图工具,再串联一个图生视频工具。最关键的一步,是把前者的图片输出,连接到后者的图片输入上。
-
汇合到终点:所有分支最后都指向一个“结束”节点,把最终生成的精美图片或视频展示给用户。
从一堆杂乱的想法,到画出草图,再到拆解成具体的步骤和工具,最后形成一个清晰的逻辑闭环,这个过程本身就非常有成就感。
希望我的这篇实践笔记能对你有所帮助。如果你有更好的思路或者已经做出了更酷的应用,欢迎在评论区和我交流!
本篇文章来源于: 阿胡的AI捕获记录



评论列表 (0条):
加载更多评论 Loading...